
不會寫代碼如何進行大數據分析——主題抽取篇
- 2020-04-10 10:43:00
- admin 原創
上一期文章中,銳研團隊介紹了如何利用云文析對文本內容進行LDA主題模型分析,最終將新聞報道主題分為五類。LDA主題模型分析是一種無監督的統計學習,而今天我們將為大家介紹另一種主題分類的方法,在云文析平臺中對應的功能是【主題抽取】。
和【主題分析】不同的是,【主題抽取】功能是用戶先自定義一套主題邏輯,設定主題邏輯詞典,即建立關鍵詞詞典,制定出每個主題下的關鍵詞,再由云文析平臺根據文本內容進行分類。這樣分類的優點是在使用者已經充分掌握文本情況或主觀層面有自己的需求,就可以根據既定的分類標準對批量文本進行分析。
還是以疫情期間收集到的1733條第一財經官網新聞數據為例,我們希望了解疫情對不同行業的影響,根據云文析已有的行業主題邏輯詞典模板(主題邏輯詞典模版2),我們開始著手分析:
一.選擇主題邏輯詞典
首先在銳研·云文析平臺找到【分析配置】-主題邏輯,點擊選擇你需要的詞典模版
行業主題邏輯詞典模板是參考《財富中國》對中國行業的分類標準,它是根據發達國家的行業界定與行業演變規則,對中國的行業進行新分類。
具體使用時如有不同需求,可以點擊左上角創建詞典,對主題邏輯進行自定義,輸入關鍵詞規則即可。
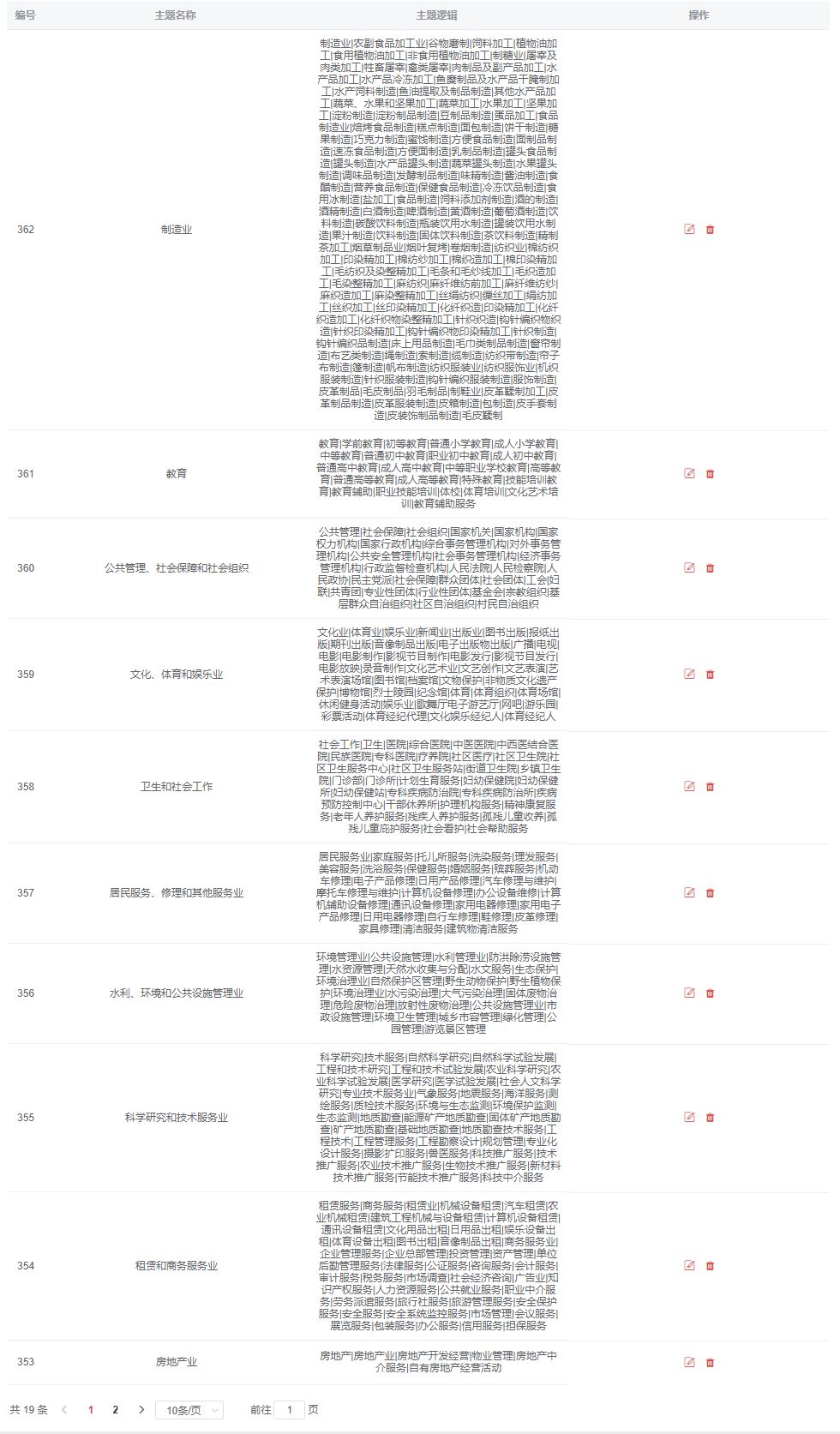
行業主題邏輯詞典模板-部分
需要注意的是,自定義主題邏輯詞典時要遵循一定的主題邏輯規則:
1.多個關鍵字同時匹配需要用 & 來連接,表示且的邏輯
2.匹配任意一個關鍵字用 | 來連接
3.支持括號()
比如,要提取“雙創”這個主題,可以用 “雙創 | (創新 & 創業)”作為主題規則,表示 只要文本中出現 “雙創”或者同時出現 “創新”和"創業”,則該文本提及“雙創”主題。
二.建立主題抽取
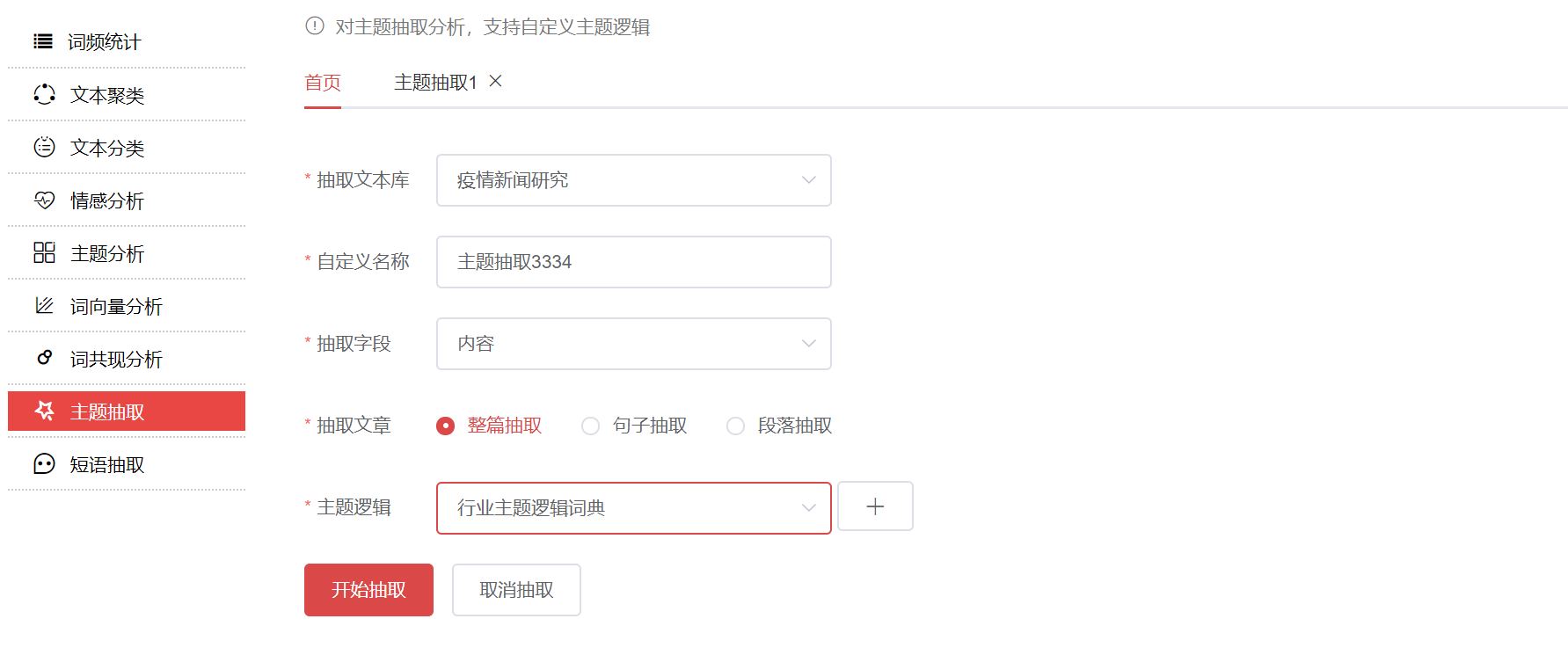
三.查看抽取結果
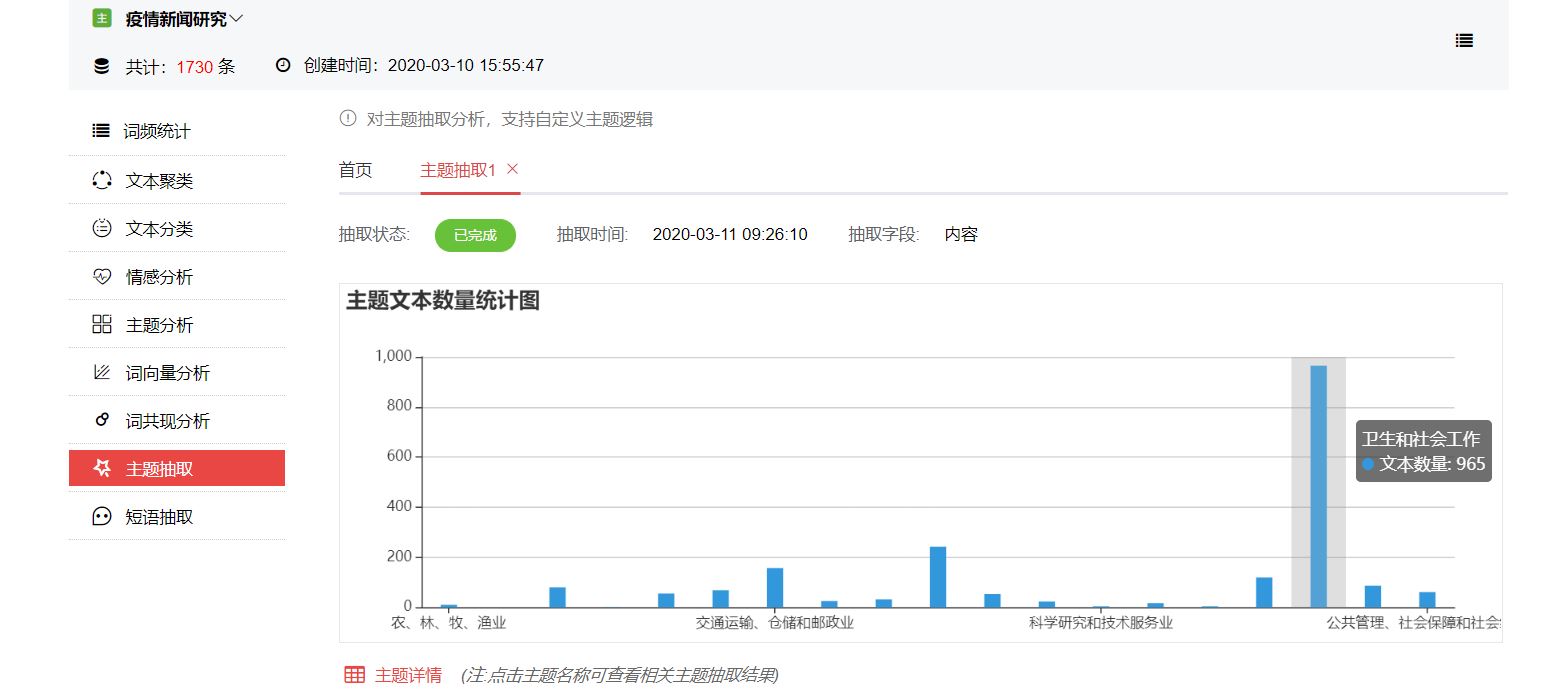
移動鼠標至條狀圖形可查看主題名稱及具體數據。結果顯示,這批報道中,衛生和社會工作相關主題的報道數量最多,達965篇;其次是金融業,文本數量達242篇;交通運輸、倉儲和郵政位列第三,文本數量達157篇;之后依次是教育、文化體育和娛樂業、制造業。
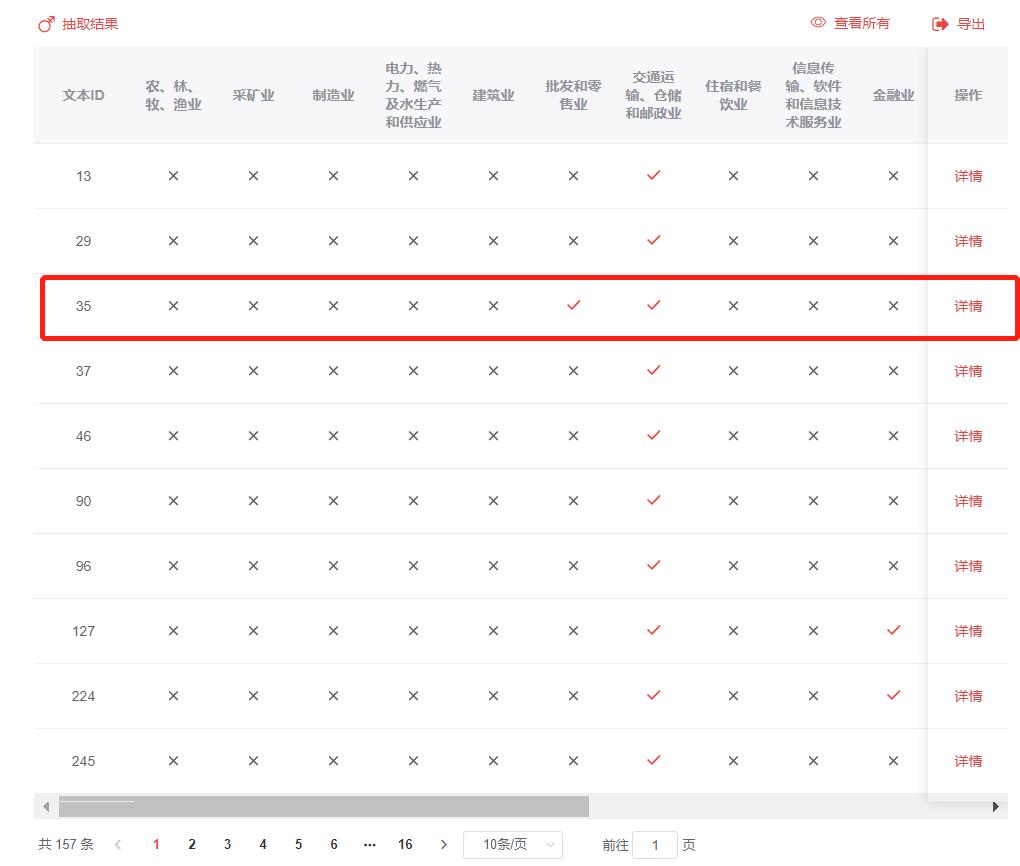
除了以柱狀圖形式展示主題文本數量,云文析還支持對抽取結果的詳情展示,我們可以查看所有主題抽取類別下的文章,標記√的表示文章分屬該類別,點擊【詳情】可查看文章具體情況,同時支持對分類數據的導出。
以文本ID為35的文章為例,該文章分屬交通運輸、倉儲和郵政業主題,點擊【詳情】后我們可以看到文章的具體內容,用以判斷分類標準是否合理以便后續分析。
銳研·云文析作為文本大數據分析與挖掘云平臺,可應用自然語言處理、機器學習、人工智能等技術對大規模文本數據進行分析挖掘,并呈現可視化分析結果。今后,銳研團隊會分享更多社會科學研究相關實用工具及案例,希望此文能為您提供一些幫助。
疫情期間,銳研云文析開放個人用戶注冊,有相關研究意向,歡迎掃描下方二維碼聯系我們的官方客服,為您開通更多權限。
