
不會寫代碼如何進行大數據分析——文本分類篇
- 2020-04-10 10:51:00
- admin 原創
一、傳統文本分類
文本分類是常見的自然語言處理,指按照一定的分類體系或規則對文本實現自動劃歸類別的過程。社會科學領域中常應用于信息索引、數字圖書管理、情報過濾等;商業領域中則常應用于分析社交媒體中的大眾情感、將新聞文章按主題分類等。
傳統的文本分類主要依靠人工完成,費時費力;基于大數據文本挖掘的文本分類則具備專業門檻,一般包括文本預處理、分詞、模型構建和分類幾個過程,社會科學領域的同仁們在各自的專業領域中是佼佼者,在復雜的機器語言面前卻是門外漢。
如何擺脫傳統文本分類的復雜繁瑣,提高文本分類的效率、降低成本,同時又能找到更便捷的輔助工具完成專業程序員才能實現的任務?
二、銳研·云文析-文本分類
銳研·云文析的文本分類功能基于機器學習分類訓練集進行,無須復雜代碼即可實現文本分類。由于文本內容差異,云文析平臺在提供系統已有分類訓練集的同時,設置了自定義分類訓練集,用戶可根據自身需要建立不同的分類訓練集以供機器學習,最終實現大批量數據的處理。
依然以疫情期間我們爬取到的第一財經相關新聞為例,本期文章將示范如何對這批數據進行文本分類:

我們想對近千條新聞文本進行報道主題的分類,首先就需要人工設定文本分類標準供機器學習,我們參考了人大RUC工作坊在《2286篇肺炎報道觀察:誰在新聞里發聲?》一文中對新聞報道主題的分類標準,以及考慮到此次疫情仍在進展中、財經類媒體的報道方向,我們將新聞報道主題分為以下十類:
防控措施、數據通報、疫情現狀及前線動態、科普/科研進展、對日常生活影響、對行業影響、其他、典型人物事件、企業社會擔當、慈善志愿活動。
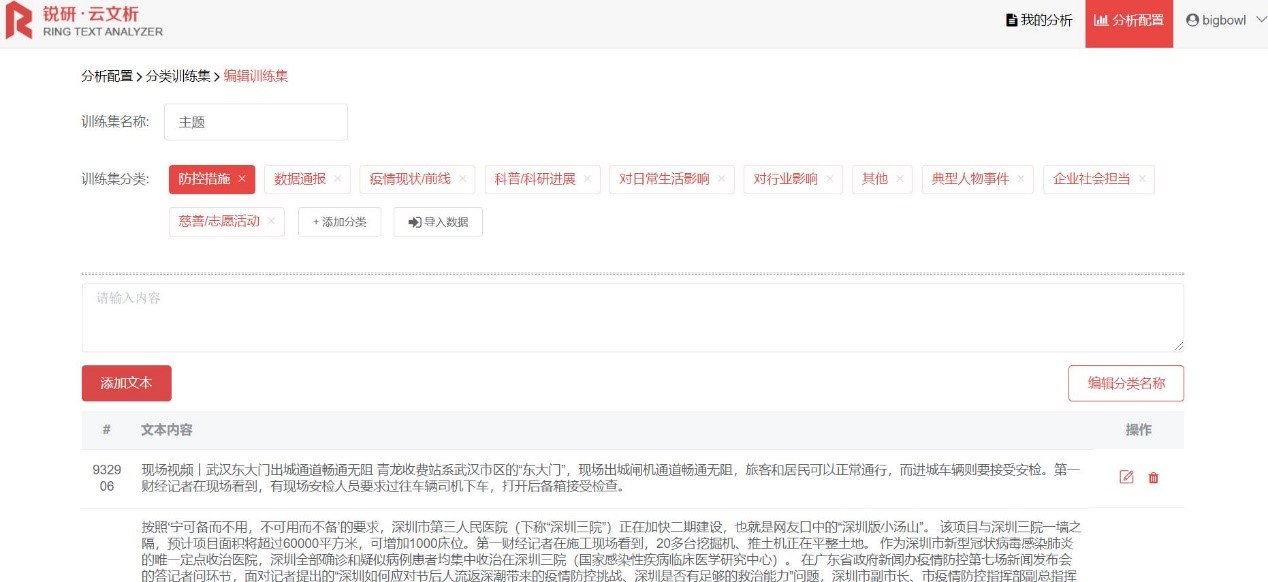
此次疫情數據共1733條,我們抽取了其中的200條對內容字段進行人工判斷,將文本內容按照上述十個類別,分別添加至各類別下供機器參考學習。添加方式有兩種,可以手動錄入文本內容,也可選擇【導入數據】按鈕導入excel文件,如下圖所示新建【主題】訓練集,不同類別可錄入多項文本內容。
Step 1 建立分類訓練集
STEP 2 進行文本分類
建立好分類訓練集后,我們就可以對文本進行分類。選擇新建文本分類,分類字段選擇【內容】字段,訓練集選擇剛才建立的【主題】分類訓練集
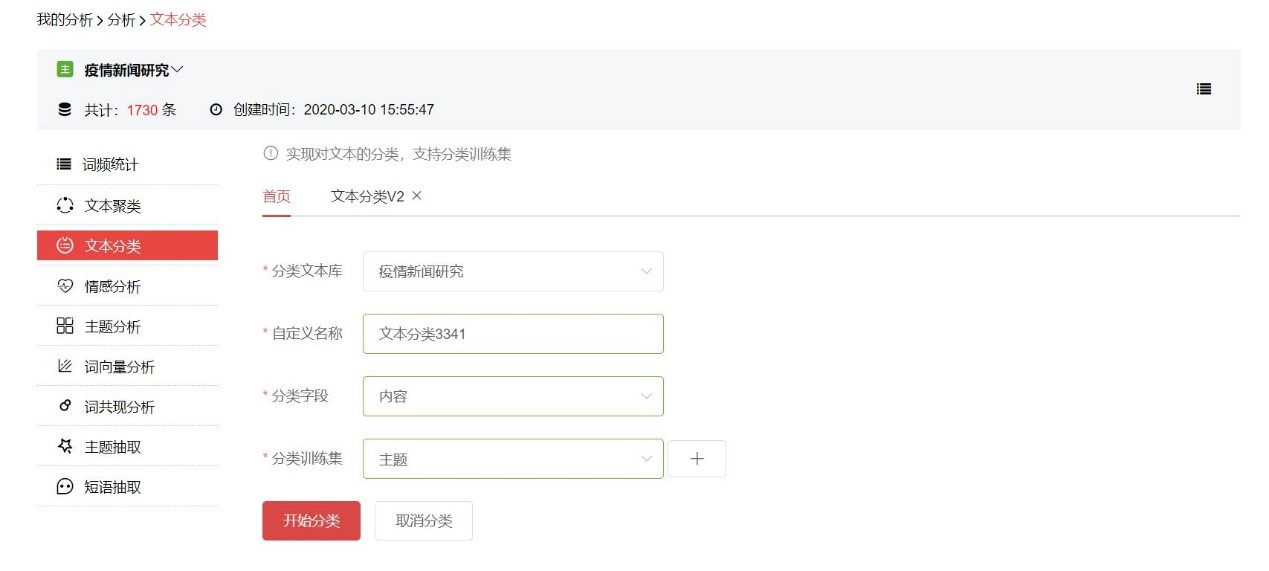
分類運行成功后,點擊圖標查看分類結果
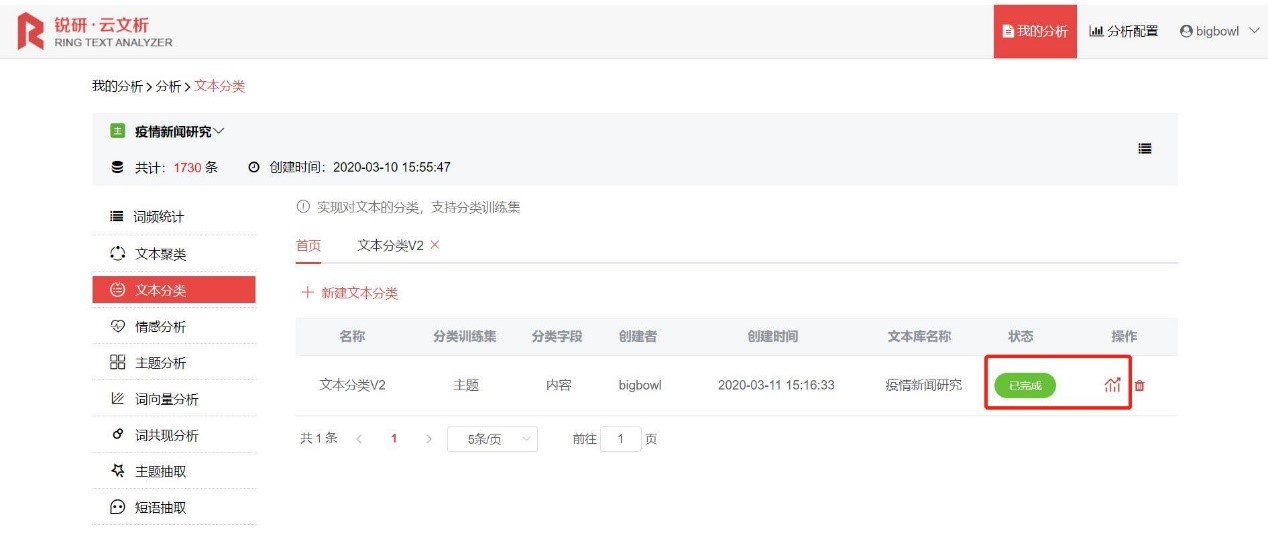
文本分類結果如下,點擊柱狀圖和餅狀圖可查看具體占比;點擊【分析結果展示】可查看不同類別下的文章內容、文章在該分類的概率等。
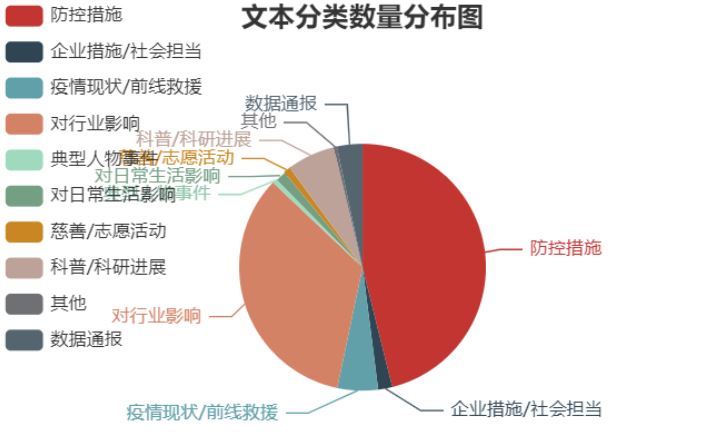
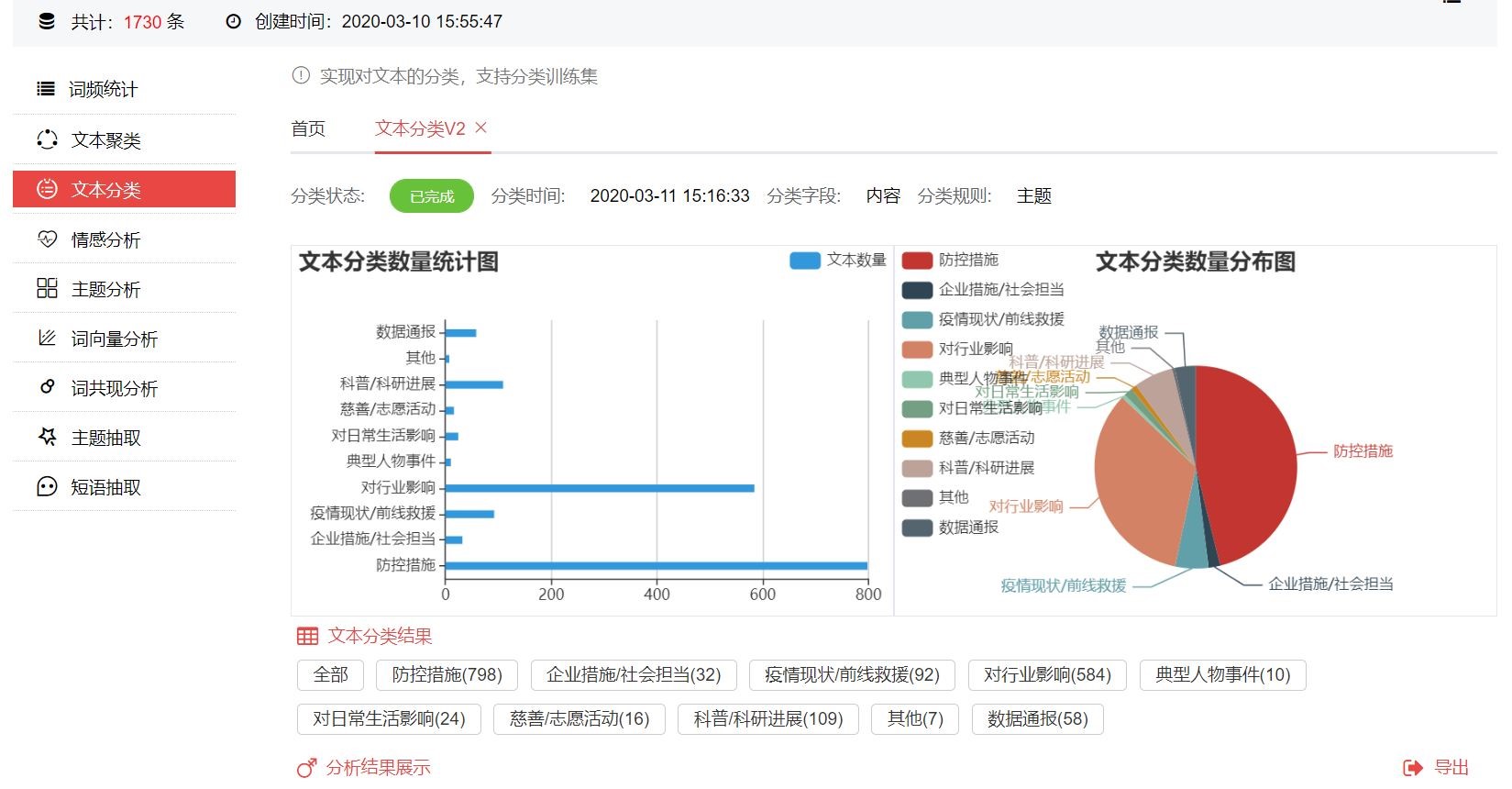 可以看出,第一財經疫情相關報道中,關于防控措施主題的報道占比最多,共798篇,占比46.13%,由于疫情仍在進展中,防控措施仍在不斷進行,相關報道數量最多較為合理;緊隨其后的是對行業影響主題的報道,共584篇,占比33.76%;而科普/科研進展、疫情現狀相關報道分別位列第三第四,占比分別是6.3%和5.32%。
可以看出,第一財經疫情相關報道中,關于防控措施主題的報道占比最多,共798篇,占比46.13%,由于疫情仍在進展中,防控措施仍在不斷進行,相關報道數量最多較為合理;緊隨其后的是對行業影響主題的報道,共584篇,占比33.76%;而科普/科研進展、疫情現狀相關報道分別位列第三第四,占比分別是6.3%和5.32%。
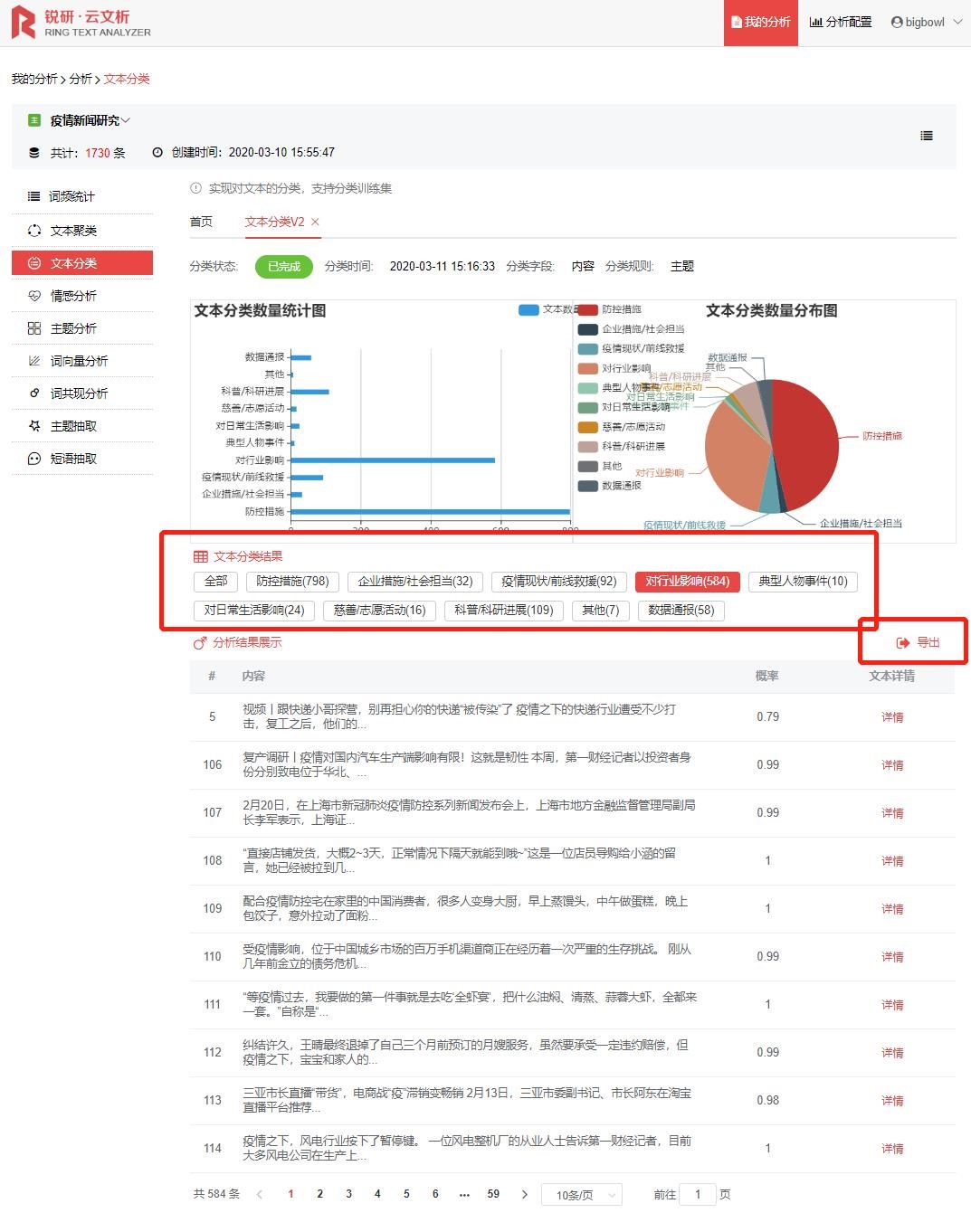
文本分類后,想要進一步研究不同類別下的文章主題,我們可以文本分類結果中選擇自己需要的類別,進行二次分析(目前銳研·云文析文本分類結果支持以excel格式導出數據),再重新建立文本庫導入數據進行主題分析。例如,第一財經作為財經類細分領域專業媒體,在此次疫情中著重報道了哪些行業,疫情對該行業的沖擊力如何?我們就可以抽取分類結果中【對行業影響】大類,導出數據后再導入云文析,進行主題分析。(詳情可見——不會寫代碼如何進行大數據文本分析——主題分析篇)
需要注意的是,文本分類結果的有效性取決于前期分類訓練集的準確性,在自定義分類訓練集時需要人工對文本進行準確預判,后期機器學習才能在人工基礎上為您進行精準的批量文本數據處理。
銳研·云文析作為文本大數據分析與挖掘云平臺,可應用自然語言處理、機器學習、人工智能等技術對大規模文本數據進行分析挖掘,并呈現可視化分析結果。今后,銳研團隊會分享更多社會科學研究相關實用工具及案例,希望此文能為您提供一些幫助。
